Multi-Agent Systems: What is a Dec-POMDP?
May-2014
This is the first post in a study on all things using Decentralized Partially Observable Markov Decision Processes (Dec-POMDP) with my professor, Prithviraj Dasgupta, who runs the CMantic Lab at the University of Nebraska, Omaha. I intend to write the summaries of what I find as blog posts, so be prepared to go on a very deep and thorough journey of how to solve problems in multi-agent planning using the Dec-POMDP’s.
Alright, so what is a Dec-POMDP?
A Dec-POMDP is a “Decentralized Partially Observable Markov Decision Process”. It’s a bunch of “agents” that are working together for a common reward. It also makes no assumptions about where an agent is in the space it is planning in. This means that if all an agent has is a touch sensor that sometimes goes off for no reason, this process will design a “policy” that will most effectively handle the variability in sensor data.
In the real world, it is very common to not have perfect data.
Let’s introduce the example given in Cooperative Decision Making.
Two star-crossed agents trying to meet
In this example, there are two robot agents that are trying to intersect. They have been placed down in a world that they have a map for, but that their navigation systems can’t move around in with 100% reliability. We won’t go into worlds that aren’t pre-mapped in this post.
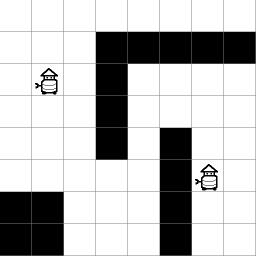
Now imagine that robots only move in their desired direction 60% of the time (with probability of 0.6). They move or stay still with probability 0.1 for each possibility. If this were the only uncertainty, the type of decision process to solve it would be called a Markov Decision Process, or “MDP”.
If the agents only have a touch sensor and it goes off for no reason 0.1 of the time, they can’t trust their motor data or their sensor data completely. They don’t know exactly where they are. Planning must be done in a different “space”. In a POMDP, this is called a “belief space”.
Because we also have another agent and we cannot be sure of the information that agent has, this becomes a “Dec-POMDP”. A Dec-POMDP is useful when all agents have a common goal. If you can’t guarantee a common goal, the problem becomes a “Partially Observable Stochastic Game”.
In this case, treating this as a “Dec-POMDP” is appropriate, as both agents want to meet in the same place. If there was another agent trying to stop them, a “POSG” would be more appropriate.
Tune in next time, when we cover policy trees and stochastic controllers.